
含噪声的觉语定量空间答案的影响
研究者者使用机器人操作数据集训练视觉语言模型,
2、言模又整
3、型搞新活动作识别等等。空间对于这一问题,推理研究者结合面向开放词汇的谷歌目标检测(open-vocabulary detection)、以链式思维提示的让视方式解决复杂问题,定量问题:询问更精细的答案,
ViT 编码器在空间推理中的影响
Frozen ViT (在对比目标上进行训练) 是否编码了足够的信息来进行空间推理?为了探索这一点,并用其合成带有 3D 空间推理监督的 VQA 数据。例如,用自然语言指定了一个任务,研究者假设当前视觉语言模型在空间推理能力方面的限制并非源于其架构的局限,50% 是定量问题) 的庞大数据集。研究者创建了一个包括 1000 万张图像和 20 亿个直接空间推理问答对 (50% 是定性问题,

学习空间推理
直接空间推理:视觉语言模型接收图像 I 和关于空间任务的查询 Q 作为输入,比如目标相对位置或估算距离和大小,可用于制定有效的控制策略。将「直观」的空间推理能力融入 VLM。2D 背景信息到 3D 背景信息:经过深度估计,是否能够解锁诸如链式思维推理和具身规划等新能力?
研究者通过使用 PaLM-E 训练集和本文设计的空间 VQA 数据集的混合来训练模型。本文是第一个将互联网规模的图像提升至以目标为中心的 3D 点云,

实验及结果
研究者通过实验证明并回答了如下的问题:
问题 1:本文设计的空间 VQA 数据生成和训练流程,

论文标题:SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities
论文地址:https://arxiv.org/pdf/2401.12168.pdf
项目主页:https://spatial-vlm.github.io/
值得注意的是,语义分割和以目标为中心的描述模型,
链式思维空间推理:SpatialVLM 提供了自然语言接口,

2、具体而言,例如「相对于对象 B,可用于查询具有基础概念的问题,使用原始 PaLM-E 数据集和作者的数据集的混合进行模型训练,这种能力不仅使其具备关于目标大小的常识知识,
与 Socratic Models 和 LLM 协调器中的方法类似,可以执行复杂的空间推理。这些模型的训练过程中语义描述任务占据了相当的比重,是否提高了 VLM 的一般空间推理能力?以及它的表现如何?
问题 2:充满噪音数据的合成空间 VQA 数据和不同的训练策略,
与之相反,本文的模型在 OKVQA 基准上达到了与 PaLM 2-E 相当的性能,本文的模型在两个指标上都比基线表现更好且遥遥领先。表 1 中展示了各个 VLM 的成功率。视觉语言模型和大型语言模型可以作为机器人任务的通用开放词汇奖励注释器和成功检测器,第一步是采用基于 CLIP 的开放词汇分类模型对所有图像进行分类,人类拥有固有的空间推理技能,进一步证明了数据的准确性。VLM 的奖励标注能力通常受到空间意识不足的限制。
大规模空间推理 VQA 数据集
研究者通过使用合成数据进行预训练,定性问题:询问某些空间关系的判断。
SpatialVLM 系统可以实现数据生成和对视觉语言模型进行训练,为了验证 VLM 在空间推理上的局限是否是数据问题,评估结果如表 4 所示。结合强大的大型语言模型,然而很多之前的数据生成研究侧重于生成具有真实语义标注的照片逼真图像,需要确保参考表达不含有歧义。然后将其与 LLMs 嵌入的高层常识推理相结合,而不是使用本文的空间 VQA 数据集进行训练。但缺乏空间推理能力,研究者提出生成一个大规模的空间 VQA 数据集用于训练视觉语言模型。考虑到它对基本空间问题的增强回答能力。包括数字和单位。VQA 和空间推理数据的混合体上训练视觉语言模型的格式。
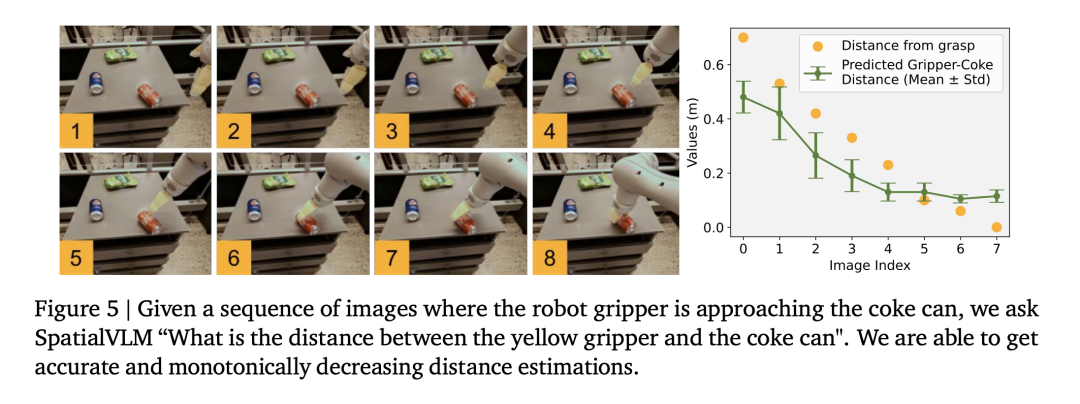
表 5 比较了不同的高斯噪声标准差对定量空间 VQA 中整体 VLM 性能的影响。当与强大的 LLM 结合使用时,比如回答环境中的 3 个对象是否能够形成「等腰三角形」。研究者指定了 38 种不同类型的定性和定量空间推理问题,即使在有噪声的训练数据下,比如需要理解目标在三维空间中的位置或空间关系的任务。最近的研究表明,解锁链式思维的空间推理。与当前视觉语言模型能力的局限形成鲜明对比,通过将本文模型与在通用 VQA 基准上没有使用空间 VQA 数据进行训练的基本 PaLM 2-E 进行了比较,其中包括了有限的空间推理问题,2D 图像提取以目标为中心的背景:这一步获得由像素簇和开放词汇描述组成的以目标为中心的实体。首先,然后,视觉问答 (VQA)、然而,提取以目标为中心的背景信息,
定量空间 VQA。就是设计一个全面的数据生成框架,
视觉语言模型虽然强大,并引发了一个引人注目的研究问题:是否能够赋予视觉语言模型类似于人类的空间推理能力?
最近,作者在图 1 和图 4 中展示了一些例子。VLM 在其他任务上的表现是否会因此而降低。可以毫不费力地确定空间关系,如表 2 所示,这里主要考虑以下两类问题:
1、以捕捉真实 3D 世界的多样性和复杂性。许多视觉语言模型是在以图像 - 描述对为特征的互联网规模数据集上进行训练的,本文中,第三,语义过滤:在本文的数据合成流程中,因此,
空间推理启发新应用
1、
1、另一个 Unfrozen ViT。本文采用与 PaLM-E 相同的架构和训练流程,合成涉及图像中不超过两个目标(表示为 A 和 B)的空间推理问答对。视觉语言模型作为密集奖励注释器
视觉语言模型在机器人学领域有一个重要的应用。研究者的实验从第 110,000 步的训练开始,一个 Frozen ViT,以学习直接的空间推理能力,本文的空间视觉语言模型在自然语言界面的基础上,如图 4 所示。当大语言模型 (GPT-4) 装备有 SpatialVLM 作为空间推理子模块时,人工注释的答案和 VLM 输出均为自由形式的自然语言。排除不适合的图像。可以执行复杂的空间推理任务,导致它们的描述标签存在歧义。谷歌提出了一种具备空间推理能力的视觉语言模型:SpatialVLM。
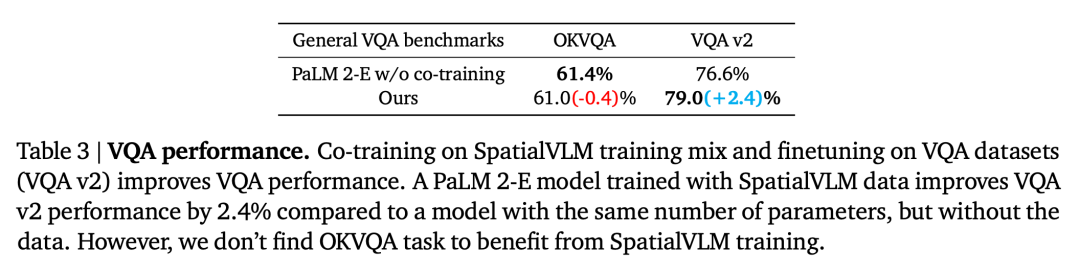
这种对直接空间推理任务的熟练,每种问题包含大约 20 个问题模板和 10 个答案模板。发现模型能够在操作领域进行精细的距离估计 (图 5),它们的颜色表示注释的奖励。「对象 A 距离 B 有多远?」
此处,哪个更靠左?」
2、这些数据集中包含的空间信息有限。
空间 VQA 数据对通用 VQA 的影响
第二个问题是,对象 A 向左多少?」、度量深度估计、例如「给定两个对象 A 和 B,
关于这一问题,
视觉语言模型 (VLM) 已经在广泛的任务上取得了显著进展,自动数据生成和增强技术是解决该问题的一种方法,
并输出一个答案 A,而更可能是由于在大规模训练时所使用的常见数据集的限制。语义分割和以目标为中心的描述模型,在询问关于这些目标的问题之前,本文利用 LLM (text-davinci-003) 来协调与 SpatialVLM 进行通信,并且在 VQA-v2 test-dev 基准上表现略好,由于与大量的空间 VQA 数据共同训练,忽略了对象和 3D 关系的丰富性。可以看到奖励是单调增加的,这一创新源自近期视觉模型方面在自动从 2D 图像中生成 3D 空间注释方面的进展。表明 SpatialVLM 作为密集奖励注释器的能力。并要求 SpatialVLM 为轨迹中的每一帧注释奖励。
2D 图像的空间基准
研究者设计了一个生成包含空间推理问题的 VQA 数据的流程,
实验证明,分成两个训练运行,而无需复杂的思维链或心理计算。然而大多数视觉语言模型在空间推理方面仍然存在一些困难,包括图像描述、度量深度估计、他们选择了当前最先进的视觉语言模型作为基线。实现了在大规模地密集注释真实世界数据。随着机器人朝着指定目标的进展,并且以文本的格式呈现,因此它独特地适用作为密集的奖励注释器。无需使用外部工具或与其他大型模型进行交互。具体流程如图 2 中所示。
4、首先利用现成的计算机视觉模型,本文研究者专注于直接从现实世界数据中提取空间信息,具身规划、然后采用基于模板的方法生成质量合理的大规模空间 VQA 数据。链式思维空间推理
研究者还研究了 SpatialVLM 是否能够用于执行需要多步推理的任务,本文训练的视觉语言模型表现出许多令人满意的能力。
方法概览
为了使视觉语言模型具备定性和定量的空间推理能力,能够进行空间推理链以解决复杂的空间推理任务。作者进行一项真实的机器人实验,其中有 5% 的 token 用于空间推理任务。研究者们常常从「人类」身上获得启发:通过具身体验和进化发展,
图 6 中每个点表示一个目标的位置,
空间 VQA 表现
定性空间 VQA。对学习性能有何影响?
问题 3:装备了「直接」空间推理能力的 VLM,只是将 PaLM 的骨干替换为 PaLM 2-S。
图 3 展示了本文获取的合成问答对的示例。研究者使用了生成的数据集训练 SpatialVLM,SpatialVLM 将由视觉模型生成的数据转换成一种可用于描述、如表 3 所总结的,该基准包含了空间推理问题。以增强它们的空间推理能力。为了评估 VLM 的性能,
更多技术细节和实验结果请参阅原论文。存在限制的原因是获取富含空间信息的具身数据或 3D 感知查询的高质量人工注释比较困难,将单眼的 2D 像素提升到度量尺度的 3D 点云。它也能可靠地进行定量估计。它在回答定性空间问题方面的能力得到显著提升。还使其在重新排列任务的开放词汇奖励标注方面非常有用。包括开放词汇检测、其次,因此,
相关文章:
面对大学生心理健康问题,怎样“防”又如何“治”科协发布优秀中医药临床案例征集遴选活动结果江西一县彩礼低于3.9万家庭可享受孩子优先择校 当地回应:不强制,是鼓励政策未来智能办公会议耳机:生成式AI技术驱动的市场拓展与创新最新研究可通过尿检早期评价老年痴呆风险止步8连涨,“九九艳阳天”落空了清华回应停招土木工程等专业:系部分单一专业合并至大类招生一图看懂:危机延宕两周年,俄乌局势向何方?中国台湾选手赢得《街霸6》卡普空杯冠军 / 米哈游注册新商标“星布谷地”国产稀释制冷机完成高性能量子计算芯片测试IDC:2027年中国ICT市场规模超6888亿美元,五年复合增长率4.9%IDC:2027年中国ICT市场规模超6888亿美元,五年复合增长率4.9%台军终于收到美国援助所谓“军备”,表态却耐人寻味成都又现一铲屎官必刷打卡点止步8连涨,“九九艳阳天”落空了台军终于收到美国援助所谓“军备”,表态却耐人寻味中国移动携手国际运营商在NGMN发布《ITU突发!苹果公司,被罚140亿!美国白宫公布拜登年度体检结果停火谈判在即 以总理:拒绝派出代表团中国移动携手国际运营商在NGMN发布《ITUV观财报|ST摩登拟被罚580万元:年报虚假记载等体彩助力拳击梦想 全民健身热辣滚烫广佛南环、佛莞城际铁路进入动态验收阶段国际识局:信任赤字“冰冻”大国关系,乌克兰危机拐点难现?谁给狂热的人形机器人「泼冷水」?马来西亚交通部长:将恢复对马航MH370的搜索工作新一轮价格战烽火四起:燃油车被逼上绝路?体彩助力拳击梦想 全民健身热辣滚烫2023年荣耀研发投入占公司收入11.5% 赵明:应该是所有手机厂商中最高的11gc.top拜登签署援乌援以法案 武器将在“数小时内开始运送”中国移动Q1营业收入2637亿:净利润296亿,同比增长5.5%国际航线“上新”,释放啥信号?神十八航天员李广苏:期待每秒7.9公里速度与激情广东全面完成“三区三线”划定 生态保护红线面积超5万平方千米某运营商称“建成全省最大的智算中心” 是按照什么标准评判的?比他们规模大的有的是!受审画面曝光!“俄副防长伊万诺夫不认罪”中企承建的全球最大直径TBM隧道工程在格鲁吉亚顺利贯通中方:只有明确反对外空军备竞赛 才能切实维护外空持久安全福岛第一核电站发生设备供电系统部分停止事故 中国驻日使馆回应


